



How Can I Learn Machine Learning?
Imagine a world where your computer predicts the stock market before it even happens, or an AI detects diseases years before symptoms appear. Picture a car that drives itself safely through traffic, or a shopping app that knows exactly what you want to buy before you even think about it. Sounds like science fiction, right? But this is the reality of Machine Learning (ML)—and the exciting part is, you can learn it too.
Here’s the question you’ve probably asked yourself: “How can I learn machine learning without getting lost in complex math or confusing code?” Don’t worry—you’re not alone. Every beginner faces the same challenge. But the truth is, ML is not magic—it’s a set of skills, tools, and algorithms that anyone can learn with the right approach.
Machine Learning isn’t just a skill for tech wizards or data scientists—it’s a career-transforming ability that opens doors to high-demand jobs, empowers you to solve real-world problems, and gives you the ability to create intelligent systems that impact industries and lives. From healthcare and finance to e-commerce and autonomous vehicles, ML is everywhere, shaping the future.
By the end of this guide, you’ll know:
-
What Machine Learning really is and why it matters.
-
The key types of ML and how they’re applied in real life.
-
The essential math and programming skills you need to start.
-
Hands-on projects that make learning practical, not just theoretical.
-
Advanced ML topics like deep learning, generative AI, and reinforcement learning.
This article combines insights from IBM, MIT, DataCamp, Coursera, GeeksforGeeks, and Wikipedia, making it authoritative, beginner-friendly, and actionable.
So, are you ready to unlock the power of machine learning and start building intelligent systems today? Keep reading because this guide will take you from zero to ML practitioner, step by step.
1. Why Learn Machine Learning?
Machine Learning is more than just a buzzword; it’s a career-transforming skill with far-reaching applications. Here’s why learning ML is essential:
-
High-Demand Career Opportunities: ML engineers, AI specialists, and data scientists are among the most sought-after professionals today.
-
Solve Real-World Problems: From predicting natural disasters to improving customer experience, ML enables actionable solutions.
-
Automation and Efficiency: ML allows automation of repetitive or complex tasks, saving time and reducing errors.
-
Innovation and Product Development: Build AI-powered apps, personalized services, and intelligent systems.
-
Industry Versatility: ML applies to finance, healthcare, retail, manufacturing, transportation, and more.
MIT researchers emphasize that ML is critical for modern engineering and design, helping engineers innovate efficiently and make smarter, data-driven decisions.
2. What is Machine Learning?
Machine Learning is a subset of Artificial Intelligence (AI) that allows computers to learn patterns from data and make predictions or decisions without explicit programming. Unlike traditional software, ML improves its performance as it is exposed to more data.

Real-Life Applications
-
Recommendation Engines: Netflix and YouTube suggest content based on viewing history.
-
Healthcare Diagnostics: ML predicts disease risk and patient outcomes.
-
Finance: Banks detect fraudulent transactions using ML algorithms.
-
Transportation: Self-driving cars like Tesla use ML for navigation.
-
Retail: Personalized product recommendations enhance shopping experience.
Think of ML as teaching computers to think and learn like humans—but faster, more accurately, and at scale.
3. Types of Machine Learning
ML algorithms are broadly categorized into three types:

3.1 Supervised Learning
-
Definition: Models learn from labeled data (inputs and corresponding outputs).
-
Goal: Predict outcomes for unseen data.
-
Examples: Supervised Learning is like teaching a child with flashcards the model learns from examples where the answers are already known, and then applies that knowledge to new problems.
3.2 Unsupervised Learning
-
Definition: Models work with data that doesn’t have predefined labels to identify underlying patterns and structures.
-
Goal: Discover trends, clusters, or structures in data.
-
Examples: Unsupervised Learning works like exploring a new city without a map—you look for patterns and connections in the data to understand the structure.
3.3 Reinforcement Learning
-
Definition: Models learn through trial and error, receiving rewards or penalties based on performance.
-
Goal: Optimize long-term strategies and decisions.
-
Examples:Reinforcement Learning is like training a dog—actions are rewarded or punished, and over time, the model learns the best strategy.
According to IBM, these types form the backbone of modern ML applications across industries.
4. Essential Mathematics for Machine Learning
While coding is essential, mathematics is the language of ML. You don’t need to be a math expert, but understanding the basics is critical.
-
Linear Algebra: Vectors, matrices, and transformations are foundational for data representation and neural networks.
-
Probability & Statistics: Understanding distributions, Bayesian theory, and statistical tests is crucial for predictions.
-
Calculus: Gradients and derivatives are essential for optimization algorithms in model training.
-
Linear Optimization: Used in algorithms like regression and SVM for model fitting.
DataCamp and Coursera emphasize that math knowledge makes algorithms more understandable and interpretable, reducing trial-and-error learning.
5. Programming Skills Required
Python is the most popular language for ML due to its simplicity and robust libraries. Essential libraries include:
-
NumPy: Efficient numerical computing and matrix operations.
-
Pandas: Data manipulation and cleaning.
-
Matplotlib & Seaborn: Visualization for data exploration.
-
Scikit-learn: Classical ML algorithms for regression, classification, and clustering.
-
TensorFlow & PyTorch: Deep learning and neural network development.
Practical coding experience is key. Start with small datasets and gradually build complex models.
6. Core Machine Learning Algorithms
Understanding machine learning algorithms is the heart of becoming an ML practitioner. Algorithms are the recipes that allow your models to learn from data and make predictions. Let’s break them down in an easy-to-understand way.
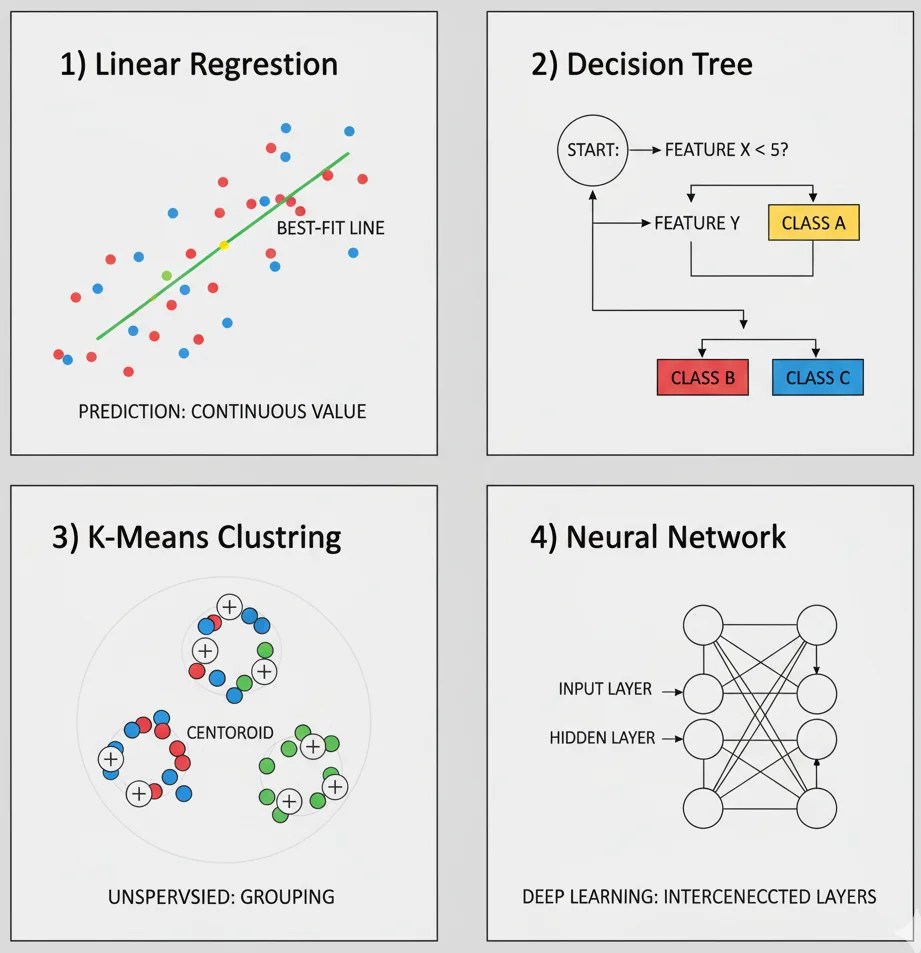
6.1 Regression Algorithms
Regression algorithms are used to predict continuous values. They’re like forecasting tools that help you answer “how much” or “how many.”
Linear Regression:
-
Predicts a value based on the relationship between input variables.
-
Example: Predicting house prices based on size, location, and number of rooms.
Logistic Regression:
-
Despite its name, it’s used for classification—predicting categories instead of numbers.
-
Example: Determining if an email is legitimate or spam.
Tip: Start with small datasets and visualize the relationship between variables using scatter plots to understand patterns before training your model.
6.2 Classification Algorithms
Classification algorithms assign data to predefined categories. Think of them as decision-making tools.
Decision Trees:
-
Uses a tree-like structure of “if-then” rules.
-
Example: Classifying whether a customer will buy a product based on age, income, and browsing history.
Random Forest:
-
A combination of multiple decision trees that boosts accuracy and minimizes overfitting.
-
Example: Predicting customer churn more reliably than a single decision tree.
K-Nearest Neighbors (KNN):
-
Classifies based on proximity to other data points.
-
Example: Handwriting recognition in scanned documents.
Support Vector Machines (SVM):
-
Finds the best boundary between classes.
-
Example: Detecting fraudulent transactions in banking.
Tip: Always visualize your data in 2D or 3D before using classification algorithms—it helps you understand how the model separates classes.
6.3 Clustering Algorithms
Clustering algorithms group similar data points together without predefined labels. It’s like sorting things by similarity.
K-Means:
-
Groups data into K clusters based on similarity.
-
Example: Segmenting customers for targeted marketing.
Hierarchical Clustering:
-
Builds a tree of clusters (nested groups).
-
Example: Organizing products into categories and subcategories automatically.
Tip: Clustering is great for exploratory analysis—it helps you discover patterns in unlabeled data.
6.4 Neural Networks & Deep Learning
Neural networks are structured to function similarly to the human brain. They’re ideal for complex problems like images, text, and audio.
-
Used in image recognition (e.g., identifying objects in photos).
-
Applied in natural language processing (e.g., chatbots, sentiment analysis).
-
Utilized in speech recognition (e.g., voice assistants).
Tip: Start with simple feedforward networks and small datasets like MNIST. Gradually explore convolutional and recurrent neural networks for images and sequences.
Key Takeaways
-
Regression: Predict numbers.
-
Classification: Predict categories.
-
Clustering: Find patterns in unlabeled data.
-
Neural Networks: Handle complex, high-dimensional data.
MIT researchers highlight that hands-on practice with each type of algorithm greatly improves understanding and retention. Try implementing one small project per algorithm to reinforce your learning.
7. Hands-On Projects for Beginners
Practical experience is essential. Start with small, manageable projects:
-
House Price Prediction: Use linear regression on real estate datasets.
-
Titanic Survival Prediction: Classification project using logistic regression.
-
Customer Segmentation: Clustering with K-Means.
-
Stock Market Prediction: Time-series forecasting.
-
Spam Detection: NLP project using classification algorithms.
-
Image Classification: Deep learning project for recognizing objects.
Where to find datasets:
-
Kaggle
-
UCI Machine Learning Repository
-
GitHub
Example (House Price Prediction):
- Step 1: Import dataset from Kaggle (e.g., Boston Housing dataset).
- Step 2: Use Pandas to clean missing values.
- Step 3: Visualize data relationships using Seaborn.
- Step 4: Train a Linear Regression model using Scikit-learn.
- Step 5: Evaluate predictions with Mean Squared Error.
- Learning Outcome: Understand regression basics, data preprocessing, and evaluation metrics.
Working on projects exposes you to data cleaning, preprocessing, feature engineering, model training, and evaluation.
8. Common Mistakes Beginners Make
Learning machine learning is exciting, but beginners often make avoidable mistakes that slow down progress. Recognizing these pitfalls early can save you time and frustration. Here are the most common mistakes and how to overcome them:
1. Skipping Math Fundamentals
Many beginners jump straight into coding ML models without understanding the underlying math. Concepts like linear algebra, probability, and statistics are crucial for interpreting results and choosing the right algorithms.
Why it matters: Without math knowledge, you may blindly apply algorithms and misinterpret outputs. For example, understanding how gradients work is essential when training neural networks; without it, tweaking your model becomes guesswork.
Tip: Learn math alongside coding. Start with small exercises like computing mean, variance, or matrix multiplication in Python. Gradually, connect these concepts to real ML tasks.
2. Focusing Only on Theory Without Coding Practice
Reading books or watching courses is useful, but ML is a practical skill. Without implementing models, concepts remain abstract.
Why it matters: You may understand the theory of regression or clustering but struggle when applying it to real datasets. Theory alone doesn’t teach you data cleaning, model tuning, or debugging.
Tip: For every concept you learn, build a mini-project. For example, after studying logistic regression, try predicting Titanic survival using Python and Scikit-learn. Practice turns knowledge into skill.
3. Overfitting Models on Small Datasets
Overfitting happens when a model learns the training data too well, including noise, and performs poorly on new data. This is a common beginner mistake.
Why it matters: A model with 100% accuracy on training data may fail in the real world. Beginners often ignore validation sets and fail to test their models properly.
Tip: Always split your dataset into training, validation, and test sets. Use techniques like cross-validation and regularization to reduce overfitting. Start with simple models before moving to complex ones.
4. Ignoring Data Preprocessing and Cleaning
Many beginners assume ML is just about algorithms. However, data cleaning and preprocessing often take 70–80% of the work. Missing values, inconsistent formats, or outliers can ruin your model’s performance.
Why it matters: A perfect algorithm cannot compensate for dirty or poorly formatted data. Even small errors can lead to wrong predictions.
Tip: Learn to handle missing values, normalize data, encode categorical variables, and remove outliers. Practice preprocessing on real datasets from Kaggle or UCI ML Repository.
5. Avoiding Real-World Datasets
Beginners often practice only on small, clean tutorial datasets. While these are good for learning basics, real-world datasets are messy, incomplete, and complex. Avoiding them limits your understanding of practical ML challenges.
Why it matters: Real projects require handling missing data, imbalanced classes, and noisy inputs. Without practice, you may struggle when working on industry problems.
Tip: Gradually move from small datasets to larger, real-world datasets. Start with Kaggle competitions or open datasets, and focus on cleaning, feature engineering, and model evaluation.
IBM stresses that learning by doing, experimenting, and failing safely is the fastest path to mastery.
9. Advanced Machine Learning Topics
Once you’ve mastered the fundamentals of machine learning, it’s time to explore advanced topics that open the door to cutting-edge applications. These topics are widely used in industries like healthcare, finance, autonomous vehicles, and AI-powered content creation. Let’s dive in.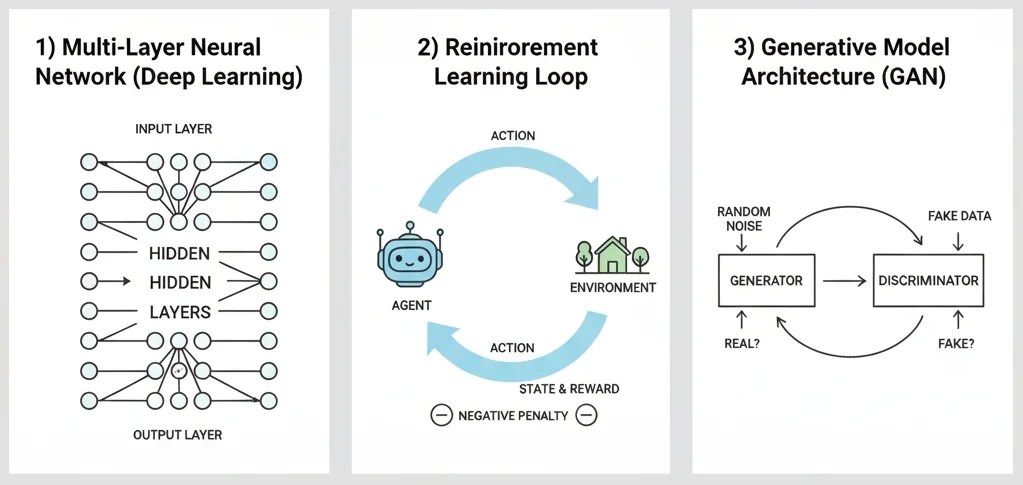
i) Deep Learning
What it is:
Deep learning is a subset of machine learning that uses multi-layer neural networks to learn complex patterns from large datasets. Unlike traditional ML algorithms, deep learning models can automatically extract features from raw data, making them ideal for image, audio, and text processing.
Why it matters:
Deep learning powers applications that require high-level understanding, such as speech recognition, natural language processing (NLP), and computer vision.
Example:
Google Photos uses deep learning to automatically recognize faces and organize photos. Similarly, virtual assistants like Siri or Alexa rely on deep learning to understand and respond to spoken commands.
Tip for Learners:
Start with TensorFlow or PyTorch, and experiment with small datasets like MNIST (handwritten digits) or CIFAR-10 (images) to understand neural network architecture, activation functions, and backpropagation.
ii) Transfer Learning
What it is:
Transfer learning involves using pre-trained models and adapting them to solve new problems. Instead of training a model from scratch—which can be resource-intensive—you leverage a model that has already learned from large datasets.
Why it matters:
It reduces computational costs and training time, while often improving accuracy, especially when the new dataset is small or specialized.
Example:
You can use a pre-trained image classification model like ResNet trained on ImageNet and fine-tune it to detect medical images for disease diagnosis.
Tip for Learners:
Focus on understanding how to fine-tune layers of pre-trained networks, and practice with platforms like Keras or Hugging Face Transformers.
iii) Reinforcement Learning
What it is:
Reinforcement learning (RL) is a type of ML where an agent learns by trial and error, taking actions in an environment to maximize cumulative rewards. Unlike supervised learning, RL doesn’t rely on labeled datasets but on feedback from the environment.
Why it matters:
RL is essential for tasks that require sequential decision-making, such as game AI, robotics, and autonomous navigation.
Example:
Google DeepMind’s AlphaGo mastered the board game Go by learning strategies through RL. Similarly, self-driving cars use RL to make safe driving decisions based on dynamic road conditions.
Tip for Learners:
Start with simple environments like OpenAI Gym, experiment with Q-Learning or Deep Q-Networks, and gradually move to complex simulations.
iv) Generative AI
What it is:
Generative AI refers to models that can create new content—text, images, audio, or even music—based on patterns learned from training data. These models don’t just analyze data; they generate entirely new outputs.
Why it matters:
Generative AI is revolutionizing creative industries, marketing, gaming, and research by producing high-quality, realistic content automatically.
Example:
-
Text: ChatGPT generates human-like conversations.
-
Images: DALL·E and MidJourney create realistic or artistic images from textual prompts.
-
Music: AI models can compose original music tracks.
Tip for Learners:
Explore GANs (Generative Adversarial Networks) or transformer-based models for generative tasks. Start with small projects like text generation using GPT models or image generation with GANs.
Key Takeaways
-
Deep Learning: Learn complex patterns from images, text, or audio.
-
Transfer Learning: Leverage pre-trained models to save time and resources.
-
Reinforcement Learning: Optimize sequential decision-making through rewards.
-
Generative AI: Create new content in text, images, music, and more.
Mastering these advanced topics will unlock high-demand skills in AI and prepare you for real-world applications that go beyond traditional machine learning.
These skills are in high demand across AI-driven industries, including healthcare, finance, autonomous vehicles, and content generation.
10. Learning Resources
Online Courses
-
Coursera: Machine Learning by Andrew Ng
-
DataCamp: Machine Learning tutorials and exercises
-
edX: Professional certification in AI & ML
Books
-
Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow
-
Python Machine Learning
Communities
-
Kaggle: Competitions, datasets, and forums
-
Stack Overflow: Problem-solving and code support
-
Reddit ML communities: Networking and collaboration
Combining courses, projects, books, and community engagement accelerates learning.
11. Step-by-Step Learning Approach
-
Learn Python and libraries (NumPy, Pandas, Matplotlib).
-
Study math fundamentals (linear algebra, probability).
-
Explore ML algorithms (regression, classification, clustering).
-
Complete small hands-on projects.
-
Experiment with advanced topics (deep learning, NLP, reinforcement learning).
-
Participate in competitions and build a portfolio.
-
Continuously read research papers and follow ML news.
MIT and IBM emphasize that structured learning combined with practice is the key to mastery.
13. Conclusion
Machine Learning is not just a skill it’s a transformative capability. By combining foundations, practical projects, algorithms, and advanced topics, anyone can become an ML practitioner. Start small, build consistently, and tackle real-world problems.
According to IBM, MIT, Coursera, and DataCamp, the combination of theory + practice + continuous learning is the fastest path to mastery. Begin today, and in months, you could be building intelligent systems that impact industries and lives.
12. FAQs
Q1: How long does it take to learn ML?
A1: Beginner: 3–6 months; Intermediate: 6–12 months with hands-on practice.
Q2: Do I need Python?
A2: Yes, it’s beginner-friendly and widely used in ML.
Q3: Is advanced math required?
A3: Basic math is enough to start; advanced topics can be learned gradually.
Q4: How can I practice with real-world data?
A4: Kaggle competitions, UCI datasets, and GitHub projects.